Python爬取新浪微博用户信息及微博内容
本文共 903 字,大约阅读时间需要 3 分钟。
大数据时代,对于研究领域来说,数据已经成为必不可少的一部分。新浪微博作为新时代火爆的新媒体社交平台,拥有许多用户行为及商户数据,因此需要研究人员都想要得到新浪微博数据,But新浪微博数据量极大,获取的最好方法无疑就是使用Python爬虫来得到。网上有一些关于使用Python爬虫来爬取新浪微博数据的教程,但是完整的介绍以及爬取用户所有数据信息比较少,因此这里分享一篇主要通过selenium包来爬取新浪微博用户数据的文章。
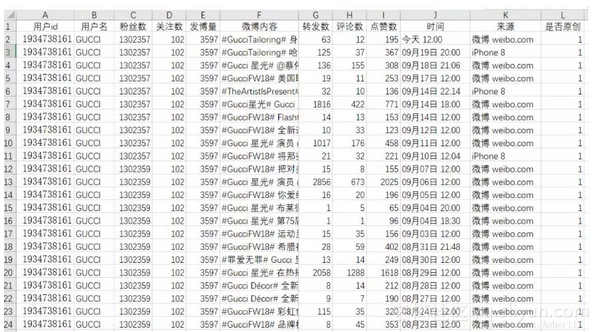
目标 爬取新浪微博用户数据,包括以下字段:id,昵称,粉丝数,关注数,微博数,每一篇微博的内容,转发数,评论数,点赞数,发布时间,来源,以及是原创还是转发。(本文以GUCCI(古驰)为例)方法 +使用selenium模拟爬虫 +使用BeautifulSoup解析HTML结果展示
步骤分解
1.选取爬取目标网址
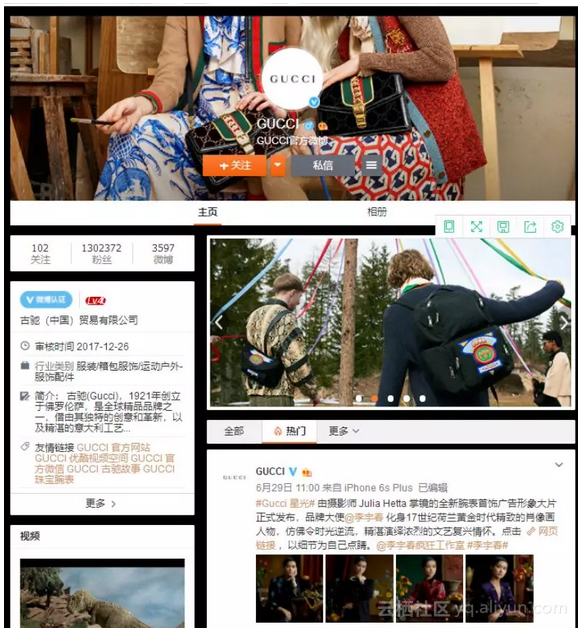
首先,在准备开始爬虫之前,得想好要爬取哪个网址。新浪微博的网址分为网页端和手机端两个,大部分爬取微博数据都会选择爬取手机端,因为对比起来,手机端基本上包括了所有你要的数据,并且手机端相对于PC端是轻量级的。 下面是GUCCI的手机端和PC端的网页展示。
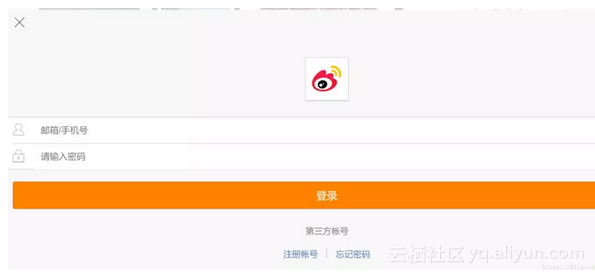
2.模拟登陆 定好爬取微博手机端数据之后,接下来就该模拟登陆了。 模拟登陆的网址 登陆的网页下面的样子
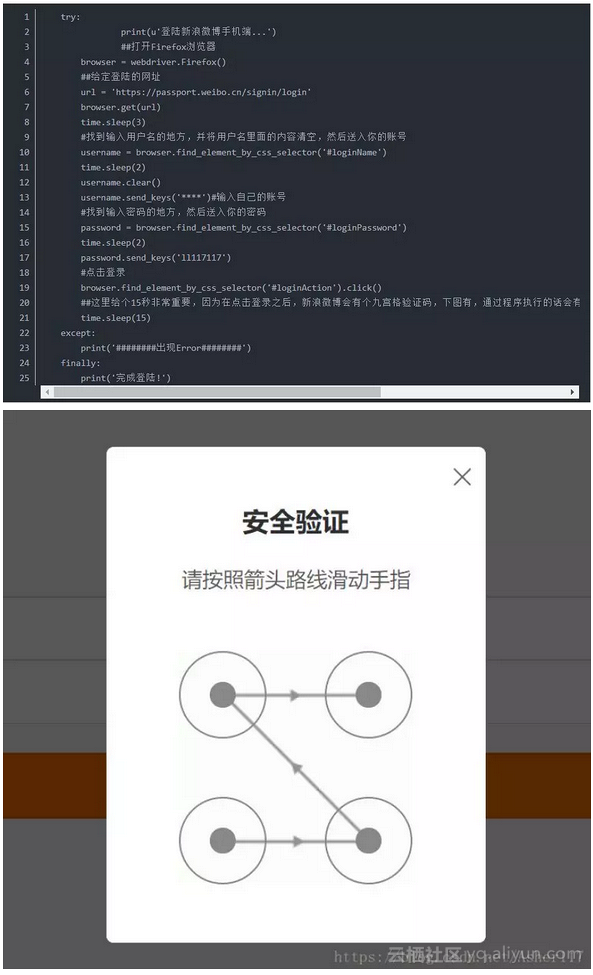
模拟登陆代码
3.获取用户微博页码
在登录之后可以进入想要爬取的商户信息,因为每个商户的微博量不一样,因此对应的微博页码也不一样,这里首先将商户的微博页码爬下来。与此同时,将那些公用信息爬取下来,比如用户uid,用户名称,微博数量,关注人数,粉丝数目。
4.根据爬取的最大页码,循环爬取所有数据
在得到最大页码之后,直接通过循环来爬取每一页数据。抓取的数据包括,微博内容,转发数量,评论数量,点赞数量,发微博的时间,微博来源,以及是原创还是转发。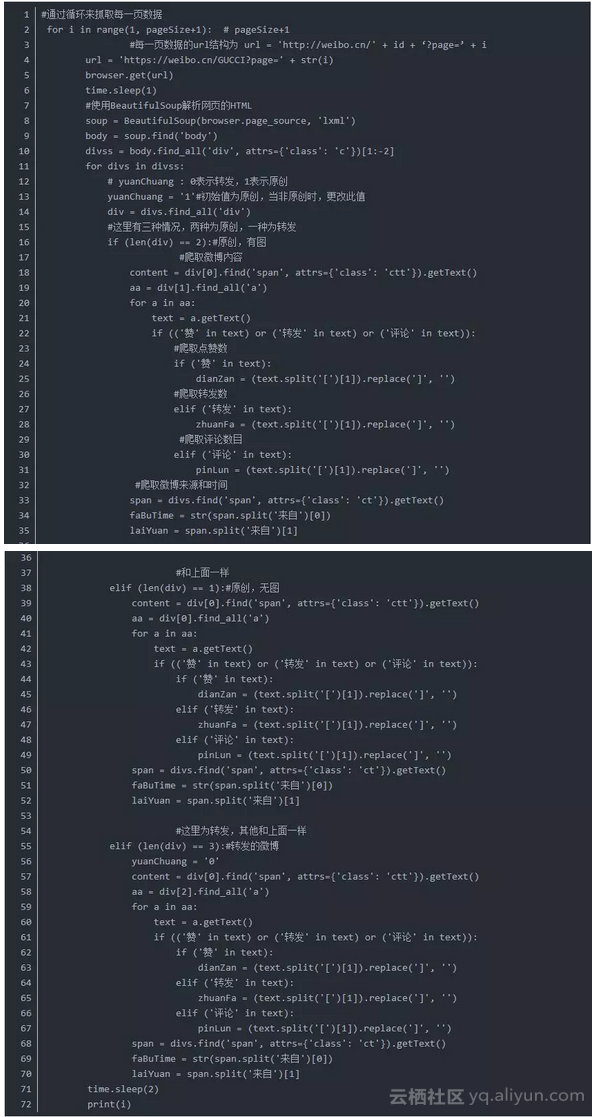
4.在得到所有数据之后,可以写到csv文件,或者excel 最后的结果显示在上面展示啦!!!! 到这里完整的微博爬虫就解决啦!!!
原文发布时间为: 2018-11-06 本文作者:Python数据之道 本文来自云栖社区合作伙伴“”,了解相关信息可以关注“”。
转载地址:http://mbjka.baihongyu.com/
你可能感兴趣的文章
PHP经典算法题
查看>>
LeetCode 404 Sum of Left Leaves
查看>>
醋泡大蒜有什么功效
查看>>
hdu 5115(2014北京—dp)
查看>>
数据结构中常见的树(BST二叉搜索树、AVL平衡二叉树、RBT红黑树、B-树、B+树、B*树)...
查看>>
PHP读取日志里数据方法理解
查看>>
第五十七篇、AVAssetReader和AVAssetWrite 对视频进行编码
查看>>
Vivado增量式编译
查看>>
一个很好的幻灯片效果的jquery插件--kinMaxShow
查看>>
微信支付签名配置正确,但返回-1,调不出支付界面(有的手机能调起,有的不能)...
查看>>
第二周例行报告
查看>>
Spring学习(16)--- 基于Java类的配置Bean 之 基于泛型的自动装配(spring4新增)...
查看>>
实验八 sqlite数据库操作
查看>>
四种简单的排序算法(转)
查看>>
Quartz2D之着色器使用初步
查看>>
多线程条件
查看>>
Git [remote rejected] xxxx->xxxx <no such ref>修复了推送分支的错误
查看>>
Porter/Duff,图片加遮罩setColorFilter
查看>>
黄聪:VMware安装Ubuntu10.10【图解】转
查看>>
Centos 6.x 升级openssh版本
查看>>